Откуда ИИ черпают информацию
Поскольку все больше и больше людей обращаются к чат-ботам с искусственным интеллектом, чтобы получить ответы на свои вопросы, стоит обратить внимание на то, откуда берутся эти ответы ИИ и какие платформы являются наиболее популярными источниками ответов ИИ.
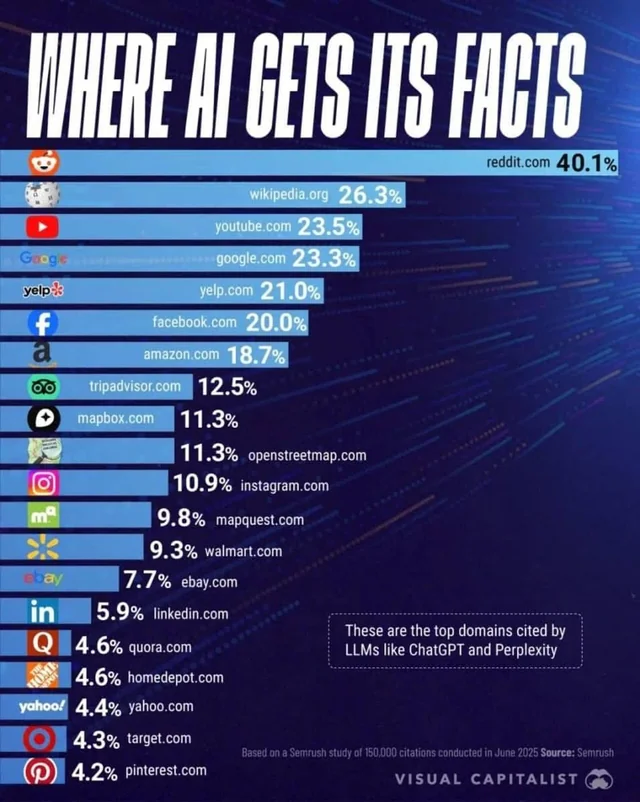
Компания Semrush провела свое исследование по поводу того, где именно LLMs модели ИИ (Google Search Overviews, Google AI Mode, ChatGPT и Perplexity) черпают информацию при поиске: в исследовании использовали 5 тысяч ключевых слов и 150 тысяч цитат LLM.
Согласно этому исследованию, Reddit является лидером по количеству ответов ИИ, значительно опережая Википедию и YouTube.
Преимущество Reddit заключается в том, что он наполнен информацией, полученной от пользователей, то есть эти ответы написаны реальными людьми, а система рейтинга с помощью голосования за и против позволяет легко найти самые ценные ответы по данной теме.
Говорят, что песню "3 сентября" раскручивали, чтобы прикрыть то, что было в Беслане.
Кто-нибудь может сделать ИИ-версию песни про это?
Немного возможного текста:
День, когда врала Симоньян,
Типа, там детей очени мало –
И приказ штурмовать был дан.
Я календарь переверну –
И снова врёт нам Симоньян.
И Соловьёв, и кто ещё –
Перечислять противно нам.
Третье сентября, день Беслана.
День, когда врала Симоньян,
Врёт она теперь постояннно
.... (здесь не придумал, можете всё поменять, лицензия WTFPL)
Попросил ChatGPT выбрать и порекомендовать мне небольшой планшет для чтения.
Задачу он понял правильно: сам ChatGPT вначале подтвердил, что будет искать планшет на 8-9 дюймов.
Потом присылает список-табличку:
• iPad Mini (6th Gen)
• BOOX Nova Pro
• Samsung Galaxy Tab A 8.0
• LG G Pad 5
• ZTE K92 Primetime
Странная подборка. Плюс у половины списка моделей какие-то странные левые характеристики. Думаю, откуда он их взял? Иду по ссылке, попадаю на сайт с этой левой подборкой и понимаю, что статья на сайте написана ИИ ))))
Так что интернет стремительно наполняется ИИ-сгенерированным шлаком, который в свою очередь становится очередным питанием для ИИ - и так по кругу.
И отдельная программа для локального запуска llm на домашнем компе: anything llm.
В них можно загрузить целые документы, ссылки на сайты, на ролики на Ютубе и всю информацию она языковая модель будет искать только в указанных источниках.
Таким образом можно учиться выбирая из больших объемов информации нужную в данный момент. Или например искать в чем сходятся и в чем расходятся мнения из указанных источников.
Это все инструменты и если их использовать правильнее то и результаты будут лучше.
А если натренированному генератору текстов доверить свое здоровье и жизнь то чтош... Дело Дарвино будет жить пока живут люди
PS Ежели кому любопытно, нахрена она нужна, эта последовательность используется телефонами для установления связи со станцией.
en.m.wikipedia.org
Можно, конечно, нагенерить и держать в памяти, но тоже лишняя сложность, так как есть достаточно простая формула, чтобы посчитать на лету.
Это уровень на шаг дальше копирования Википедии в качестве ответа и будет означать, что ИИ стали кормить умными книжками.
Разработчики ИИ-тов для разных профессиональных сфер вроде как пичкают их исключительно релевантными для соответствующей сферы данных, а дешёвых "всезнаеек" для широкой публики достоверной узкопрофильной информацией не пичкают. И в ближайшем обозримом будущем таковое положение, полагаю, не изменится.
Т.е. любой ответ будет простой и неполный, получить ответ на сложный профессиональный вопрос почти невозможно.
ПыСы: проверил: ситуация немного улучшилась, Gemini получил доступ к аннотациям статей и патентов, но пока не к самим текстам.
Но он и туда не ходит, пользуется Reddit-ом.
Просите к запросам ссылки. Зная источники, проще судить о достоверности. Если нужны исследования с достоверно научными результатами, то добавляйте:
Use peer-reviewed articles. Provide links.
Потому что сама эта штуковина работает 1) усреднением, а средний человек, если и выучил когда-то статистическую значимость, то за несколько лет забудет (и с удовольствием), 2) на отдельные темы существуют так называемые RAG, когда ответ выдается в соответсвии с сохраненными в памяти ИИ текстами.
Use peer-reviewed articles. Provide links.
В общем, как обычно - доверяй, да проверяй. Плюс в том, что поставляется материал для проверки.
Я лишь однажды попросил ИИ проверить точность перевода на английский... Было грустно и смешно. Теперь только сам и с помощью друзей. А для серьёзных дел я лучше заплачу гораздо больше профессиональному редактору, чем в разы меньше, но глупой машине, которая городит несуразности одна на другую. Эту схему токенов Сема Альтман сломать не сможет, и в конце концов выйдет "крокодилий хвост в полночь", как в том старом рассказе "Гениак" Андрея Балабухи про супергениальную машину, которая оказалась супершизофренником.
Нет, вы все как хотите, но лично эта хрень ни к чему.
А про реддит ничего не скажу, никогда в жизни не пользовался и не читал до сегодняшнего дня. Сегодня полюбопытствовал. Десяти минут хватило, чтобы больше никогда туда не заходить.
Во первых, я ненавижу читать длинющие ветки обсуждений. Во вторых, какое кредабилити у того, что кто-то написал на каком-то форуме? Почему я должен доверять хрен знает кому? И ссылаться я и тоже должен на непойми кого с какого-то редита? С тем же успехом можно спрашивать что-либо на людной площади. И то, если спрашивать перед каким нибудь университетом, то шансов на нормальный ответ будет гораздо больше.
Во первых, я ненавижу читать длинющие ветки обсуждений. Во вторых, какое кредабилити у того, что кто-то написал на каком-то форуме?
Диды искали!
Нет, здесь не должен лажать если что-то касается простой грамматики/словаря. Если что-то узко специальное, то да, вполне, может сгаллюцонировать .
Бывает, вон в Аргентине президент - либертарианец.
"У каждой аварии есть имя, фамилия и должность." Л.М. Каганович
Ну не нарком же, в самом деле!
Никто не готов к тому, что железка мудреная будет отвечать за принятие решений. Ибо где отвественность там и полномочия, а вот этим люди делиться не готовы.
Так что товарищ майор, ну или общественный обвинитель в суд будут тащить кого-то с именем, фамилией и должностью. И как обычно - стрелочника.
Неудивительно, что у людей на постсоветском пространстве столько заблуждений и страхов, которые поиск в интернете не развеивает, а только усиливает.
Пару раз присутствовал на презентации нашего софта (я один из программистов), как там всё красиво расписывали и волосы на лысине становились дыбом 😄
Но ваш аргумент от этого не пошатнулся.
Разорвёт нафиг.
Будет давать бесполезные советы и тут же клянчить, чтобы вы пометили этот ответ как полезный и правильный 😄
Примечательно, что если начинаешь задавать наводящие вопросы, новые модели тут же включают заднюю и начинают предлагать новый вариант, иногда работающий.
Точно, как лучшие друзья Пафнутия с одного азиатского субконтинента
Т.е. ума "сообразить", что так делают только, когда снимают рекламу еды, ему уже не хватило.
Там ещё было несколько таких примеров и от ChatGPT и т.д.
Поэтому, когда мне приводят аргумент "А вот мне ChatGPT сказал...", в моих глазах IQ сказавшего понижается на порядок.
Think of how stupid the average person is, and realize that half of them are stupider than that.” —George Carlin.
Более молодое поколение слушает ИИ, как Библию и верит на все 100%, даже не перепроверяя информацию.
Далеко не нужно ходить, у меня есть несколько знакомых (диапазон 30-40 лет), которые делают так-же. И сколько я, "компьютерщик", им не объяснял, что не нужно настолько им верить и всегда перепроверять... куда там. Каждый раз одно и то же.
Хотя, какая-то часть их ходит в церковь, так что да... мой аргумент пошатнулся 😄
Как людям из каждого утюга уже несколько лет постоянно рассказывают (причём в первую очередь главы и представители всех этих нейросетей), так большинство людей всё это и воспринимает.
Лень сейчас искать ролики, как руководство ЧатГПТ в интервью ездили по ушам ведущей и зрителям и рассказывали что вот уже очень скоро это будет реальный Интеллект.
Думминг отстучал вопрос: «Гекс, ты знаешь что-то, чего я не знаю?»
Муравейник засуетился и почти сразу выплюнул ответ: «Практически все».
Думминг более тщательно сформулировал вопрос с должным количеством пунктов и условий. Вопрос был сложным и многословным, вопрос волшебника, который успел сегодня поесть только один раз, и никто другой не сумел бы даже понять, что Думминг имел в виду, но муравьи судорожно заикали, и Гекс выдал: «Мы имеем дело со смертью Матушки Ветровоск».
В нем были ответы. Он знал, какова природа вещей, и почему вещи такие, какие они есть, и какие они на самом деле, и что все это значит.
Ответчик мог ответить на любой вопрос, если вопрос правильно поставлен. И он хотел, нет, он жаждал отвечать!
Что же еще делать Ответчику?"
вот прям растрогался 😄
прям вечер воспоминаний 😄
В качестве основного источника информации - это катастрофа 😒
Ситуация всё больше напоминает вот этот анекдот.
— Из тумбочки.
— А кто их туда кладет?
— Моя жена.
— Ну она-то где их берет?
— Я ей даю.
— А вы откуда берете?
— Из тумбочки.
- Мы хотим узнать: зима будет теплая или холодная?
- А зачем вам?
- Если холодная, мы пойдем собирать хворост про запас, я если теплая -
не будем.
Шаман думает: скажу теплая, а вдруг будет холодная - они все замезнут и
меня замочат. А если скажу холодная - они собирут хворост, и даже если
зима будет теплой - ничего страшного. И говорит:
- Однако, чукчи, зима будет холодная!
Чукчи ушли, а шаман нервничает: вдруг все-таки зима теплая будет, зря
хворост собирали. Пойду, думает, к советскому метеорологу, спрошу. Он же
ученый - все знает.
Приходит на станцию, а там сидит заросший метеоролог, да еще с
сильнейшего бодуна. Шаман спрашивает:
- Скажи мне, однако, зима холодной будет?
Метеоролог в окно глянул:
- Ага!
- Ой, спасибо, а как вы это узнали, однако?
- А вон чукчи хворост собирают!!!
Есть такое дело.
Хуже то, что я наблюдаю сейчас, а именно фактически ставшее обязательным использование ИИ при обучении и обязательное использование ИИ при работе. Говорят что пр приеме в АйТи команду Сбера требуют продемонстрировать умение писать код используя ИИ, и это плохо.
Короче, пока что оно постоянно лажает на мало-мальски сложных вопросах - и никто ни у кого работу еще и близко не отнимает (по-крайней мере, мою 😄 ). Весь вопрос в том - действительно ли мы подходим к очередной "зиме искусственного интеллекта"? Или где-то в лабах корпораций кто-то уже пилит принципиально новые архитектурные подходы, которые помогут обойти ограничения LLM в которые мы почти уперлись. Говорят, чем-то таким Илья Суцкевер вроде как-раз занят. Ну, поглядим.
Или тут как с вождением автомобиля - одно ДТП на миллион км от ИИ означает, что ИИ пока рано пускать за руль, но одно ДТП на 100 тыс км от человека - это нормально? 😄
AI - это, блин, не робот-программист в коробочке. Это инструмент. И с точки зрения эффективности работы уметь им пользоваться - гораздо лучше, чем не уметь им пользоваться.
(Если что, то я использую чатик каждый день - вот уже несколько лет. В том числе и по работе. Мне не нужно рассказывать, как им пользоваться. Более того, я даже понимаю как он устроен: что такое нейросети, LLM, трансформеры, токены и вот это вот все. Я просто, черт побери, написал об ограничениях текущей технологии. Я не луддит, от меня не требуется защищать технологический прогресс).
ЧатГПТ выдал всё ту информацию которую я прочитал до него, просто всё сразу и удобно скомпилировано, т.е всё тоже самое без ответа.
Потом на reddit прочитал, что в этом проекторе есть скрытое инженерное меню. Зашел в него, там всё на китайском. Сфоткал, ЧатГПТ всё перевёл и там оказалась та самая настройка, которую я искал.
Это всё к вопросу про ИИ и, как тут некоторые писали (фантазировали) с год назад, что вот скоро выпустят 5ю версию ЧатГПТ и это уже будет реальный ИИ который сможет думать. Хрен там, даже и близко нет.
Кстати о новой версии - мне кажется что она "поглупела", что явно не так, но видимо прикрутили какие то фильтры, и выдача стала грустней.
Мне тоже неизвестно про инженерное меню в большинстве устройств, но если Вы пришлете его фотку на английском, я без труда его для Вас переведу. Возможно я не могу думать 😄
Мне тоже неизвестно про инженерное меню в большинстве устройств, но если Вы пришлете его фотку на английском, я без труда его для Вас переведу. Возможно я не могу думать 😄
А взаимосвязь такая, что всю эту информацию что у этого проектора существует инженерное меню, как в него зайти и какие пункты на китайском в нем есть- всё это я нашёл в интернете. И потом (когда я ему показал это меню) ЧатГПТ мне по всем пунктам меню мне всё перевёл и рассказал какой там пункт за что отвечает.
Вот только он не сделал главного- он не смог соотнести мой изначальный вопрос с тем, что оказывается ответ на него есть в этом меню. И в интернете тоже я ничего такого не нашёл, то есть есть только информация о существовании меню и что люди искали ответ на мой вопрос. Но ответ никто не написал что нужно именно в этом меню включить конкретный пункт.
То есть ЧатГПТ не сделал простой мыслительный шаг- он не соотнес мой вопрос- существование меню- существование в нем нужного пункта. Не потому что это невозможно, а просто в интернете этого никто не написал.
Или ты всё-таки раскрыл миру этот секрет?
Или ты всё-таки раскрыл миру этот секрет?
Сами же говорите, думать не умеет. Так будет уметь.
Сами же говорите, думать не умеет. Так будет уметь.
А это кажется вы и говорили, что вот подождите, выпустят 5ю версию (тогда еще 3я была), вот тогда и будет уже реальный Интеллект. Не дословно, но смысл был такой.
Теперь, как я вижу, надо еще немного подождать...
Если хотите поспорить- то вон выше есть видео, где мужик хорошо всё рассказывает, поспорьте с ним.
Теперь, как я вижу, надо еще немного подождать...
Я как-то спросил у чятика сколько было титулов Большого Шлема у Надаля с 2011 года, он сказал что где-то примерно 13.
Я говорю - как это примерно? Можно ж точно посчитать. Он, да - вот список, даёт список из 13 побед, и говорит что их 11, и это сто пудов точный ответ)
Невзоров: 59.9%.
Здесь в комментах тоже как бы не весь диапазон взглядов представлен.
Те данные, что бэкапили физически в другое облако - другой датацентр - сохранились, но там вдруг(!) оказалось отнюдь не всё, ибо экономили.
Да, мне тоже доводилось находить полезную информацию, но откровенного мусора очень много...



